来源:搜狐科技
在搜索引擎中输入一个问题,通常会获得多个候选答案,此时人们会通过对比判断,选择或归纳出最优答案。如果是机器来做这件事,会是怎样的呢?
近日,百度的研究者从两种不同角度出发,探索了多文档校验方案对多文档阅读理解的作用,分别提出了多文档校验模型 V-NET 以及一种强化学习训练机制,进而让机器能够预测出更好的答案,提高准确率。目前,这两项研究工作的论文均已被 ACL 2018大会录用:
·《Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification》
·《Joint Training of Candidate Extraction and Answer Selection in Reading Comprehension》
国际计算语言学学会(Annual Meeting of the Association for Computational Linguistics,简称 ACL)是自然语言处理与计算语言学领域最高级别的学术会议。ACL 会议涵盖语言分析、信息抽取、自动问答、对话系统、机器翻译等各个领域,每年发表的论文都反映了自然语言处理领域的最新研究进展和学术动向,受到学术界和工业界的广泛重视。据报道,本届会议共计有1551篇论文进入审查阶段(1021 长篇,530 篇短篇),录用率约为20%。一个研究机构在 ACL 上发表的论文数量和质量也在一定程度上代表了该团队在本领域的研究实力和领先程度。

机器阅读理解(Machine Reading Comprehension)是指让机器阅读文本,然后回答和阅读内容相关的问题。其技术可以使计算机具备从文本数据中获取知识并回答问题的能力,是构建通用人工智能的关键技术之一。简单来说,就是根据给定材料和问题,让机器给出正确答案。阅读理解是自然语言处理和人工智能领域的重要前沿课题,对于提升机器智能水平、使机器具有持续知识获取能力具有重要价值,近年来受到学术界和工业界的广泛关注。
随着机器阅读理解技术的发展,阅读理解任务也在不断升级,从早期的“完形填空形式”,发展到基于维基百科的“单文档阅读理解”,如以斯坦福 SQuAD 为数据集的任务。并进一步升级至基于 web(网页)数据的“多文档阅读理解”,这一形式的典型代表是以微软 MS-MARCO、百度 DuReader 为数据集的任务。
目前,针对不同的阅读理解任务,研究人员已经设计出多种模型,并取得初步成效。然而在多文档阅读理解任务中,由于与问题相关的文档很多,带来的歧义也更多,由此可能最终导致阅读理解模型定位错误的答案。面对这些问题,人类的思考模式通常为:先找到多个候选答案,通过对比多个候选答案的内容,选出最终答案,由此来找到准确率最高的答案。沿着这种思路,百度从不同角度探索了多文档校验方案对多文档阅读理解的作用,进而让机器能够更好地理解内容,给出正确答案。
在论文《Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification》中,百度提出了一种新的多文档校验的深度神经网络建模方法 V-NET,通过注意力机制使不同文档产生的答案之间能够产生交换信息互相印证,从而预测出更好的答案。V-NET 是一个端到端的神经网络模型,如下图所示,该模型同时使用三个不同的模块分别从三个方面来预测答案:答案的边界预测模块、答案内容预测模块和多文档的答案验证模块。在 MARCO 和 DuReader 数据集上,V-NET 模型效果显著优于其他系统。
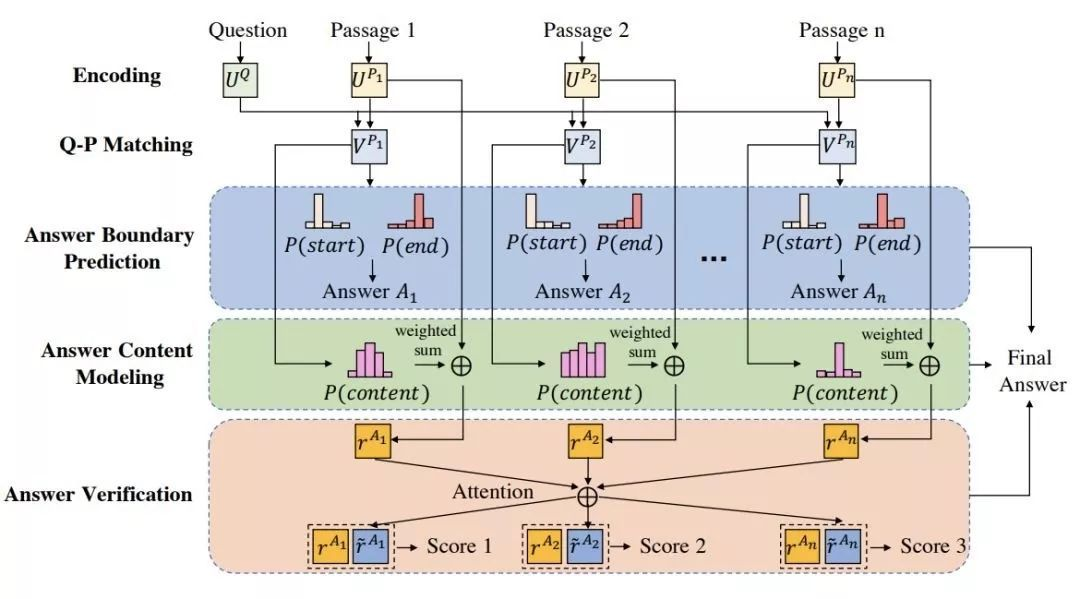
V-NET 模型的整体架构
在论文《Joint Training of Candidate Extraction and Answer Selection in Reading Comprehension》中,百度利用强化学习的方法对串行的多文档阅读理解模块进行联合训练。在传统的问答系统中,“抽取候选答案->综合选出答案”串行的模式非常常见,但通常将这两个步骤看成独立的模块分开处理。其实,这两个模块之间的联系非常密切,同时也由于数据集没有提供各文档的可能的候选答案,因此百度将各文档中的候选答案视为隐变量,用神经网络分别建模对应的两种行为(action),并在多文档校验模块中引入相关性矩阵建模候选答案之间的关联关系。在此基础上采用强化学习的方法联合训练,以提升最终答案与真实答案的匹配程度,也就是直接根据评价指标同步训练两阶段的模型。
此外,针对多文档阅读理解任务,百度自然语言处理团队此前已经发布了面向真实搜索应用的最大中文开放领域阅读理解数据集 DuReader,包含30万问题、150万文档和72万答案。并基于此数据集举办了2018中文阅读理解技术评测(http://mrc2018.cipsc.org.cn/),评测共有1062个队伍报名,累计提交结果1489次。该评测推动了机器阅读理解技术,尤其是中文阅读理解技术的发展。DuReader 数据集以及评测方法的论文也均被 ACL2018阅读理解研讨会(Workshop on Machine Reading for Question Answering)所录用:
·《DuReader: a Chinese Machine Reading Comprehension Dataset from Real-world Applications》
·《Adaptations of ROUGE and BLEU to Better Evaluate Machine Reading Comprehension Task》
百度在自然语言处理(NLP)领域已经过十余年积累与沉淀,具备了最前沿、最全面、最领先的技术布局,不仅专注于前瞻技术探索,更致力通过技术应用解决实际问题。据悉,上述两项技术均已直接应用于百度搜索引擎产品中,提升机器阅读理解的效果,它直接在搜索结果中精准定位用户输入的问题,并在显著位置呈现,为用户节约大量的宝贵时间。同时,作为百度 AI 技术的重要组成部分,这些技术还将赋能百度技术体系及智能产品中,提升用户问答需求的相应能力,最终或将通过百度技术开放渠道开放,赋能广大开发者与合作伙伴。



